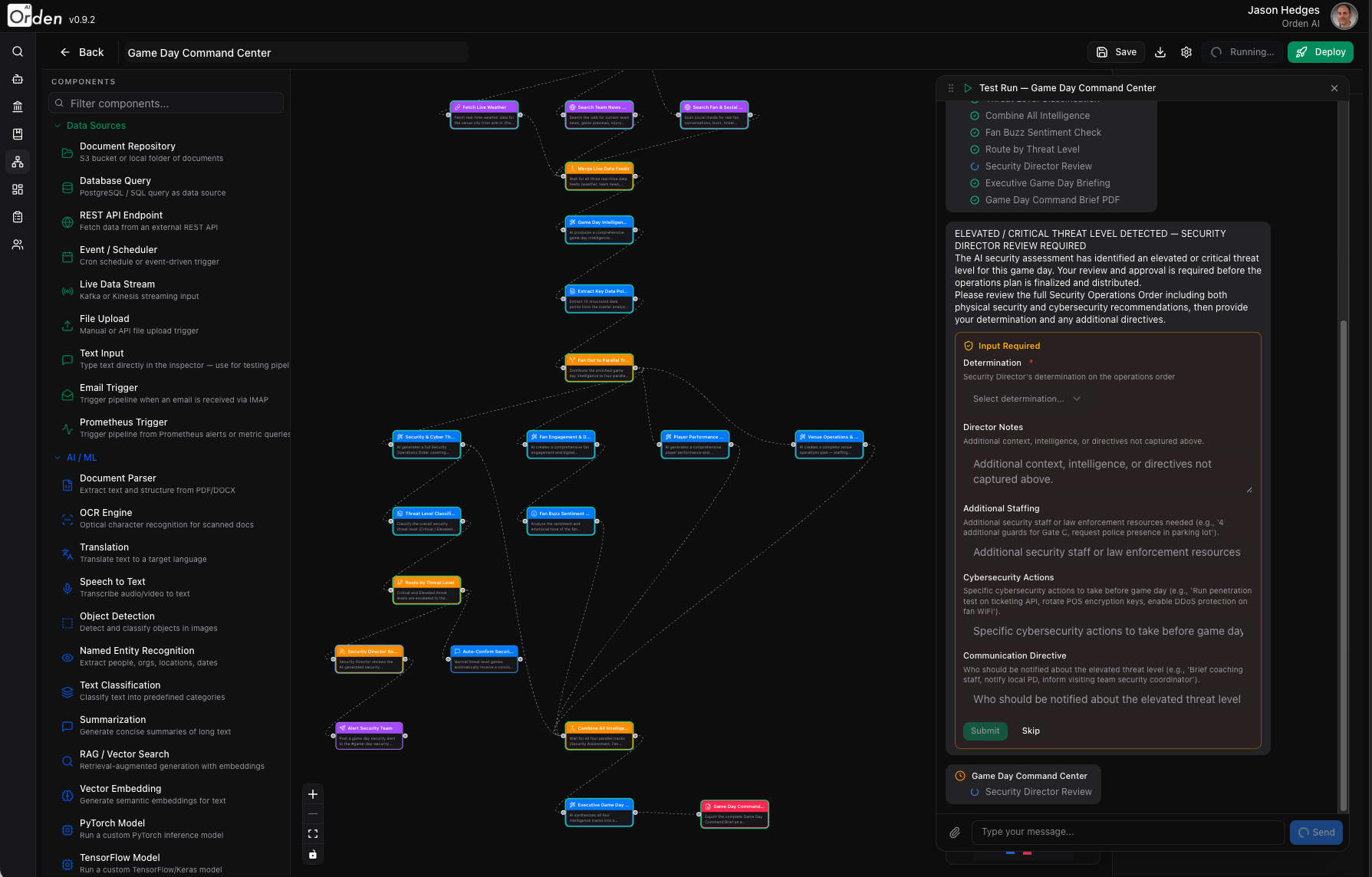
Visual Pipeline Editor
Drag, connect, deploy—or let AI build it for you
Build complex AI workflows on an intuitive canvas. Drag nodes from a categorized palette, wire them together visually, and configure each node's parameters in a side inspector. Or simply describe what you need in plain English and AI will generate a complete pipeline automatically—nodes, connections, and configurations ready to run. No YAML, no JSON, no code.
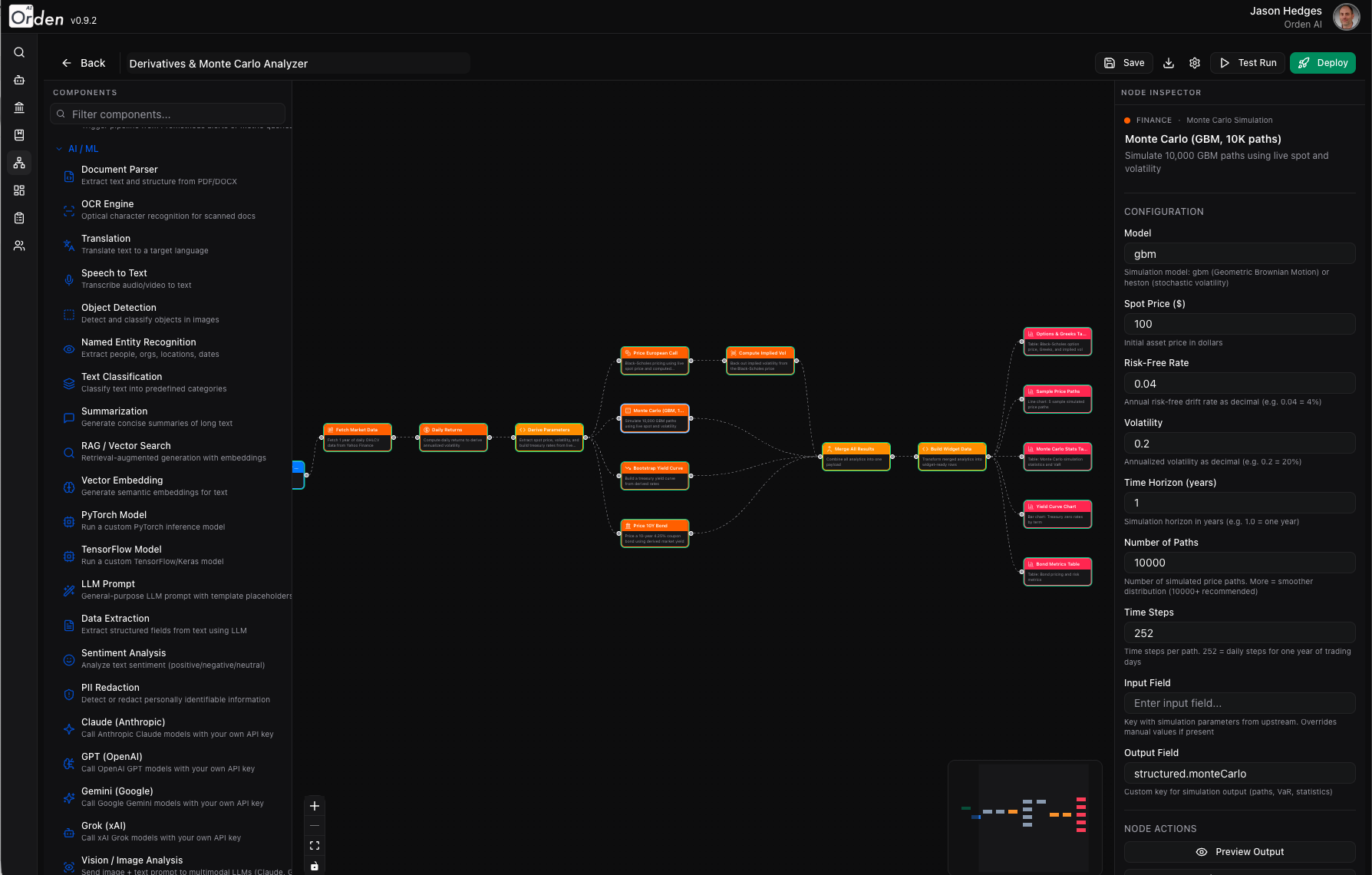
Visual pipeline editor with categorized node palette and inspector